
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 코딩규칙
- 코딩컨밴션
- 구글스타일가이드
- javascript
- 스타일가이드
- 프레임워크
- google style guide
- @keyframes
- 자기개발
- 자바스크립트
- css rule
- css규칙
- MariaDB
- 코딩가이드
- vueJS
- CSS애니메이션
- 개발회고
- 뉴스수집
- to do list
- 구글CSS
- 파이썬
- vuejs입문
- 웹스크래핑
- CSS로딩
- 로딩UI
- Vue.js
- html제거
- python
- vue-cli
- 투두리스트
- Today
- Total
코드공부방
파이썬으로 최신 부동산 뉴스를 모아서 보자! (3) (웹 크롤링/스크래핑) 본문
파이썬으로 최신 부동산 뉴스를 모아서 보자!
(웹 크롤링/스크래핑) (3)
python에서 MariaDB를 접근할땐 mysql.connector라이브러리를 사용한다. 앞서 얘기했듯이 본 포스팅에선 DB서버 구축이나 라이브러리의 설치 등의 과정은 생략하고 나중에 별도로 정리해볼 예정이다.
import mysql.connector
dbconn = mysql.connector.connect(host='host명', user='DB 서버 접근 ID', password='DB서버 접근 PW', database='DB명', port='포트')
cursor = dbconn.cursor()
insert_data(dbconn, cursor)
dbconn.commit()
dbconn.close()
위와 같은 방식으로 db접속정보와 cursor를 insert_data함수에 같이 넘겨주면 insert_data에서 INSERT문을 실행시켜 수집한 뉴스를 DB에 INSERT한다. 그럼 아래와 같이 GetSedaily 클래스 내부의 코드에 dbconn, cursor를 파라미터로 받는 코드를 추가하고 수집한 뉴스에 대해 for문을 반복할때 insert_data 함수를 호출하는 코드를 추가 한 후 실행해보자. (테스트를 위해 부동산 일반 뉴스만 샘플로 실행시켜 본다.)
class GetSedaily :
def __init__(self, dbconn, cursor) :
self.encoding = get_encoding('https://sedaily.com')
self.dbconn = dbconn
self.cursor = cursor
# 부동산 일반
def normal(self) :
url = 'https://sedaily.com/NewsList/GB07'
soup = get_soup(url, self.encoding)
news_list = soup.select('.sub_news_list li')
for news in news_list :
data = {}
# 뉴스 기사 제목
title = news.select_one('.text_area h3').get_text().strip()
# 뉴스 요약
summary = news.select_one('.text_sub').get_text().strip()
# 썸네일 이미지 경로
# 이미지 없는 경우 예외처리
if news.select_one('.thumb img') is not None :
thumbnail_url = news.select_one('.thumb img')['src']
else :
thumbnail_url = 'none'
# 뉴스 URL
news_url = news.select_one('a')['href']
news_url = 'https://sedaily.com' + news_url
# 뉴스 코드
news_code = news_url.split('/GB')[0].split('NewsView/')[1]
# 뉴스 작성 일자
regist_date = news.select_one('.text_info .date').get_text().strip()
# 뉴스 작성 시간
regist_time = news.select_one('.text_info .time').get_text().strip()
data = {
'news_category' : 3,
'media_code' : 1,
'media_name' : '서울경제',
'news_code' : news_code,
'news_title' : title,
'news_summary' : summary,
'news_thumb_url' : thumbnail_url,
'url' : news_url,
'news_reg_date' : regist_date
}
insert_data(self.dbconn, self.cursor, data)
dbconn = mysql.connector.connect(host='host명', user='DB 서버 접근 ID', password='DB서버 접근 PW', database='DB명', port='포트')
cursor = dbconn.cursor(buffered=True)
# 서울경제
GetSedaily = GetSedaily(dbconn, cursor)
GetSedailyNormal = GetSedaily.normal()
많은 수의 뉴스가 에러로 인해 INSERT가 되지 않았다. syntax 에러인거 보니 아마도 기사 제목에 ", ' 같은 따옴표가 존재하여 쿼리문을 실행하는 부분의 문법을 해치는 것으로 의심된다. 기사 제목에서 특수문자를 제거 후 DB에 넣기로 하고 특수문자를 제거하는 함수를 추가한다.
# 특수문자 제거
def remove_sc(sentence) :
return re.sub('[-=.#/?:$}\"\']', '', str(sentence)).replace('[','').replace(']','')그 후에 수집해온 코드 중 기사 제목과 기사 요약내용을 추출할때 remove_sc함수를 이용하여 특수문자를 제거해준다.
# 뉴스 기사 제목
title = remove_sc(news.select_one('.text_area h3').get_text().strip())
# 뉴스 요약
summary = remove_sc(news.select_one('.text_sub').get_text().strip())특수문자를 제거하는 코드를 추가 후 다시 실행해보았다.

에러 없이 잘 실행이 됐다. 정말 잘 저장되었는지 DBeaver Tool 에서 조회해보았다.
SELECT * FROM TBL_LAND_NEWS_LIST;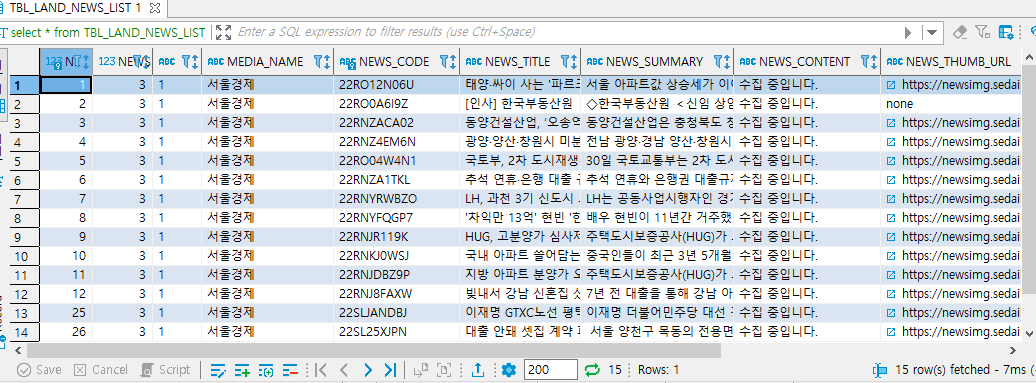
NEWS_CONTENT column은 "수집 중 입니다" 상태인데, 목록수집과 별도로 뉴스 상세화면을 조회하며 상세 내용을 수집하는 코드를 별도로 추가해주면 된다. 이는 다음 포스팅에서 진행 예정이다.
현재까지 전체 소스는 아래와 같다.
import requests
import re
import regex
import time
import os, json
from datetime import datetime
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 특수문자 제거
def remove_sc(sentence) :
return re.sub('[-=.#/?:$}\"\']', '', str(sentence)).replace('[','').replace(']','')
# 웹사이트 인코딩 방식 확인
def get_encoding(url) :
f = urlopen(url)
# bytes자료형의 응답 본문을 일단 변수에 저장
bytes_content = f.read()
# charset은 HTML의 앞부분에 적혀 있는 경우가 많으므로
# 응답 본문의 앞부분 1024바이트를 ASCII문자로 디코딩 해둔다.
# ASCII 범위 이외에 문자는 U+FFFD(REPLACEMENT CHARACTRE)로 변환되어 예외가 발생하지 않는다.
scanned_text = bytes_content[:1024].decode('ascii', errors='replace')
# 디코딩한 문자열에서 정규 표현식으로 charset값 추출
# charset이 명시돼 있지 않으면 UTF-8 사용
match = re.search(r'charset=["\']?([\w-]+)', scanned_text)
if match :
encoding = match.group(1)
else :
encoding = 'utf-8'
return encoding
# 사이트 소스 가져오기
def get_soup(url, charset) :
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'}
res = requests.get(url, headers=headers)
res.raise_for_status()
res.encoding = None
soup = BeautifulSoup(res.content.decode(charset, 'replace'), 'html.parser')
return soup
class GetSedaily :
def __init__(self, dbconn, cursor) :
self.encoding = get_encoding('https://sedaily.com')
self.dbconn = dbconn
self.cursor = cursor
# 부동산 일반
def normal(self) :
url = 'https://sedaily.com/NewsList/GB07'
soup = get_soup(url, self.encoding)
news_list = soup.select('.sub_news_list li')
for news in news_list :
data = {}
# 뉴스 기사 제목
title = news.select_one('.text_area h3').get_text().strip()
# 뉴스 요약
summary = news.select_one('.text_sub').get_text().strip()
# 썸네일 이미지 경로
# 이미지 없는 경우 예외처리
if news.select_one('.thumb img') is not None :
thumbnail_url = news.select_one('.thumb img')['src']
else :
thumbnail_url = 'none'
# 뉴스 URL
news_url = news.select_one('a')['href']
news_url = 'https://sedaily.com' + news_url
# 뉴스 코드
news_code = news_url.split('/GB')[0].split('NewsView/')[1]
# 뉴스 작성 일자
regist_date = news.select_one('.text_info .date').get_text().strip()
# 뉴스 작성 시간
regist_time = news.select_one('.text_info .time').get_text().strip()
data = {
'news_category' : 3,
'media_code' : 1,
'media_name' : '서울경제',
'news_code' : news_code,
'news_title' : title,
'news_summary' : summary,
'news_thumb_url' : thumbnail_url,
'url' : news_url,
'news_reg_date' : regist_date
}
insert_data(self.dbconn, self.cursor, data)
# 부동산 정책
def policy(self) :
url = 'https://sedaily.com/NewsList/GB01'
soup = get_soup(url, self.encoding)
news_list = soup.select('.sub_news_list li')
for news in news_list :
data = {}
# 뉴스 기사 제목
title = remove_sc(news.select_one('.text_area h3').get_text().strip())
# 뉴스 요약
summary = remove_sc(news.select_one('.text_sub').get_text().strip())
# 썸네일 이미지 경로
# 이미지 없는 경우 예외처리
if news.select_one('.thumb img') is not None :
thumbnail_url = news.select_one('.thumb img')['src']
else :
thumbnail_url = 'none'
# 뉴스 URL
news_url = news.select_one('a')['href']
news_url = 'https://sedaily.com' + news_url
# 뉴스 코드
news_code = news_url.split('/GB')[0].split('NewsView/')[1]
# 뉴스 작성 일자
regist_date = news.select_one('.text_info .date').get_text().strip()
# 뉴스 작성 시간
regist_time = news.select_one('.text_info .time').get_text().strip()
data = {
'news_category' : 3,
'media_code' : 1,
'media_name' : '서울경제',
'news_code' : news_code,
'news_title' : title,
'news_summary' : summary,
'news_thumb_url' : thumbnail_url,
'url' : news_url,
'news_reg_date' : regist_date
}
insert_data(self.dbconn, self.cursor, data)
# 부동산 분양 정보
def parcel_out(self) :
url = 'https://sedaily.com/NewsList/GB02'
soup = get_soup(url, self.encoding)
news_list = soup.select('.sub_news_list li')
for news in news_list :
data = {}
# 뉴스 기사 제목
title = remove_sc(news.select_one('.text_area h3').get_text().strip())
# 뉴스 요약
summary = remove_sc(news.select_one('.text_sub').get_text().strip())
# 썸네일 이미지 경로
# 이미지 없는 경우 예외처리
if news.select_one('.thumb img') is not None :
thumbnail_url = news.select_one('.thumb img')['src']
else :
thumbnail_url = 'none'
# 뉴스 URL
news_url = news.select_one('a')['href']
news_url = 'https://sedaily.com' + news_url
# 뉴스 코드
news_code = news_url.split('/GB')[0].split('NewsView/')[1]
# 뉴스 작성 일자
regist_date = news.select_one('.text_info .date').get_text().strip()
# 뉴스 작성 시간
regist_time = news.select_one('.text_info .time').get_text().strip()
data = {
'news_category' : 5,
'media_code' : 1,
'media_name' : '서울경제',
'news_code' : news_code,
'news_title' : title,
'news_summary' : summary,
'news_thumb_url' : thumbnail_url,
'url' : news_url,
'news_reg_date' : regist_date
}
insert_data(self.dbconn, self.cursor, data)
# DB 접속
dbconn = mysql.connector.connect(host='host명', user='DB 서버 접근 ID', password='DB서버 접근 PW', database='DB명', port='포트')
cursor = dbconn.cursor(buffered=True)
# 서울경제
GetSedaily = GetSedaily(dbconn, cursor)
GetSedailyNormal = GetSedaily.normal()
GetSedailyPolicy = GetSedaily.policy()
GetSedailyParcelOut = GetSedaily.parcel_out()
# DB 접속 종료
dbconn.close()파이썬으로 최신 부동산 뉴스를 모아서 보자! (웹 크롤링/스크래핑) (1)
파이썬으로 최신 부동산 뉴스를 모아서 보자! (웹 크롤링/스크래핑) (1) 벌써 2021년 10월이다. 맙소사.. 2020년 12월 28일에 회고 글을 작성하며 2021년엔 많은 것들을 이뤄보자라는 생각을 했었
code-study.tistory.com
파이썬으로 최신 부동산 뉴스를 모아서 보자! (웹 크롤링/스크래핑) (2)
파이썬으로 최신 부동산 뉴스를 모아서 보자! (웹 크롤링/스크래핑) (2) 앞선 포스팅에서 서울경제에서 원하는 카테고리의 뉴스 목록을 수집하여 console에 print하는 것까지 작업을 진행하였다.
code-study.tistory.com
'생산 > 부동산뉴스모아' 카테고리의 다른 글
| 파이썬으로 최신 부동산 뉴스를 모아서 보자! (4) (웹 크롤링/스크래핑) (0) | 2021.10.05 |
|---|---|
| 파이썬으로 최신 부동산 뉴스를 모아서 보자! (2) (웹 크롤링/스크래핑) (0) | 2021.10.03 |
| 파이썬으로 최신 부동산 뉴스를 모아서 보자! (1) (웹 크롤링/스크래핑) (0) | 2021.10.02 |


